CS-466/566: Math for AI
Module 04: Logistic Regression
2026-03-23
Classification vs. Regression

Will You Pass the Exam?
📋 The Scenario
- A professor is tracking student outcomes
- Measures: study hours and sleep hours
- Goal: predict Pass ✅ or Fail ❌
| Study (\(x_1\)) | Sleep (\(x_2\)) | Result |
|---|---|---|
| 5 | 7 | ✅ Pass |
| 3 | 8 | ✅ Pass |
| 1 | 3 | ❌ Fail |
| 2 | 2 | ❌ Fail |
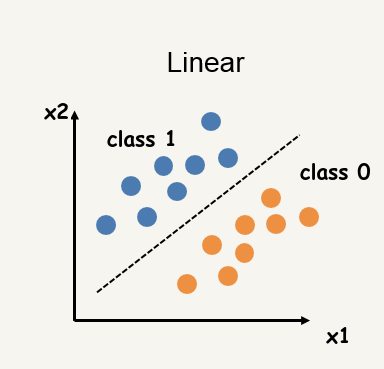
Key Question: How do we draw a line to separate the classes?
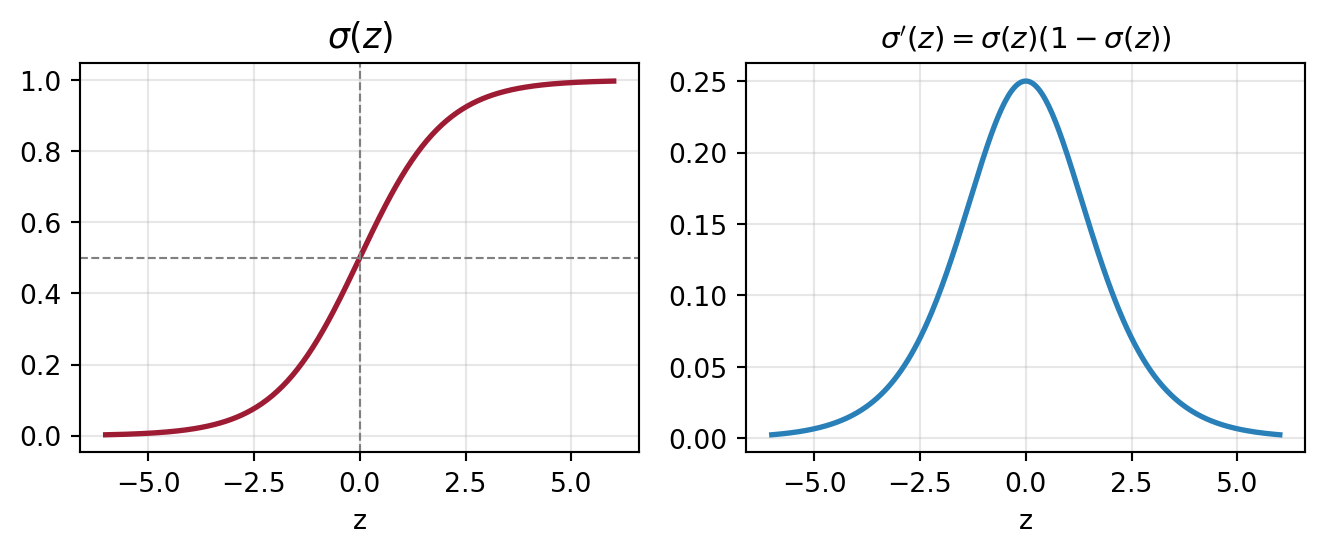
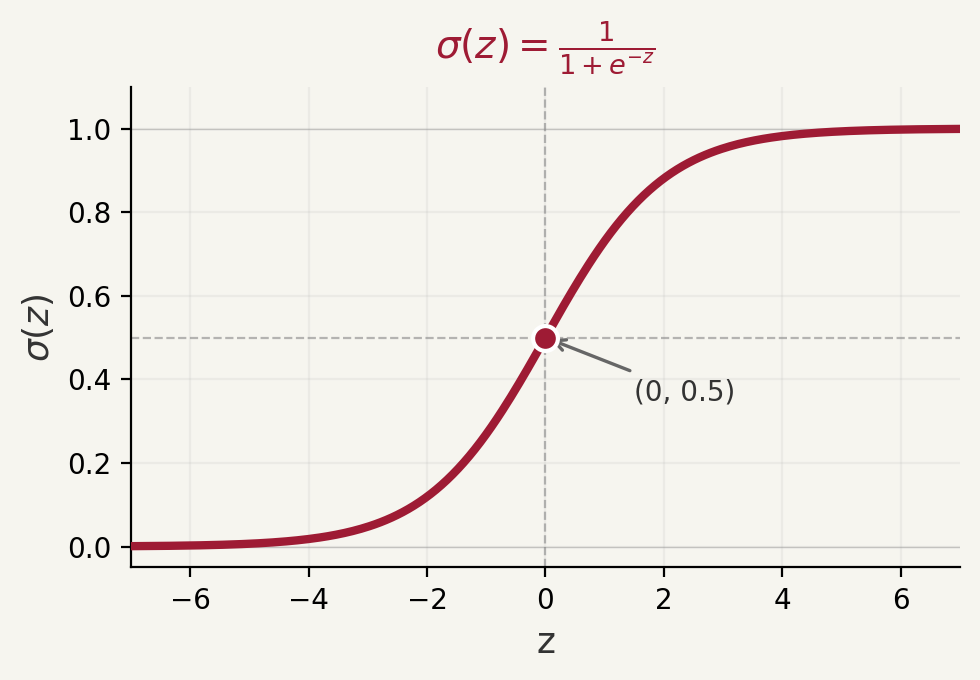
From Scores to Probabilities
Let \(z = w_1 x_1 + w_2 x_2 + \cdots + w_n x_n + w_0\) be the linear score.
We need a function that maps \(z \in (-\infty, +\infty)\) to a probability in \([0, 1]\).
\[\sigma(z) = \frac{1}{1 + e^{-z}}\]
| Input \(z\) | \(\sigma(z)\) | Interpretation |
|---|---|---|
| \(-\infty\) | \(0\) | Definitely Class 0 |
| \(0\) | \(0.5\) | Uncertain |
| \(+\infty\) | \(1\) | Definitely Class 1 |
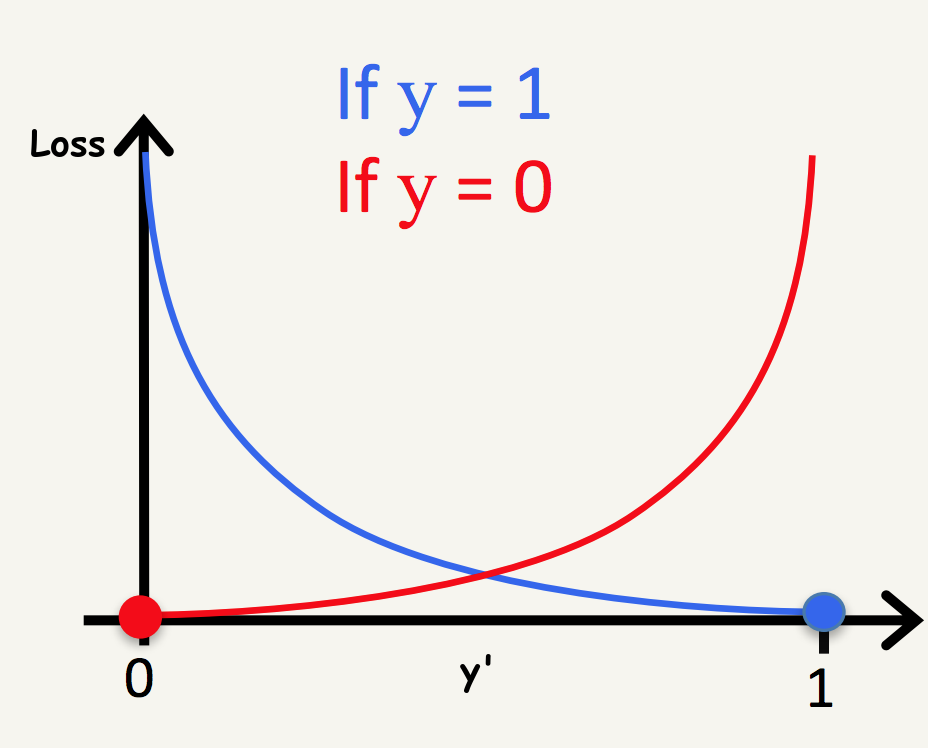
Log Loss (Cross-Entropy Loss)
When \(y = 1\): \[\color{#2980b9}{\ell = -\log(\hat{y})}\]
- \(\hat{y} \to 1\): loss \(\to 0\) ✅
- \(\hat{y} \to 0\): loss \(\to \infty\) ❌
When \(y = 0\): \[ \ell = -\log(1 - \hat{y})\]
- \(\hat{y} \to 0\): loss \(\to 0\) ✅
- \(\hat{y} \to 1\): loss \(\to \infty\) ❌
Unified: \(\quad \quad \quad \ell(y, \hat{y}) = -y\log(\hat{y}) - (1-y)\log(1-\hat{y})\)
Extending to Multiple Classes
Logistic regression is inherently binary (two classes). For \(K\) classes, we use the One-vs-All (OvA) strategy.
Procedure:
- Train \(K\) separate binary classifiers: one per class
- Classifier \(k\) predicts: “Is this example Class \(k\) or not?”
- Each outputs a probability \(\hat{y}_k = \sigma(z_k)\)
- Predict the class with the highest probability: \[\hat{y} = \underset{k \in \{1, \ldots, K\}}{\arg\max}\; \hat{y}_k\]
For \(K = 3\) classes: train 3 classifiers and pick the most confident one.
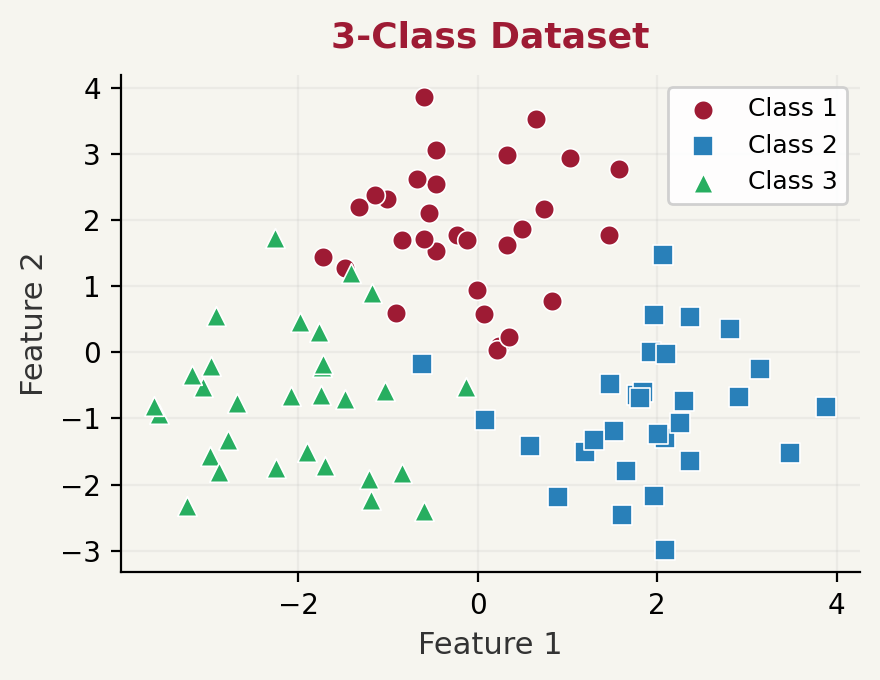
One-vs-All: Diagram

For \(K\) classes: \(\hat{y} = \underset{k \in \{1, \ldots, K\}}{\arg\max}\; f_k(x)\)
One-vs-All: Visualization
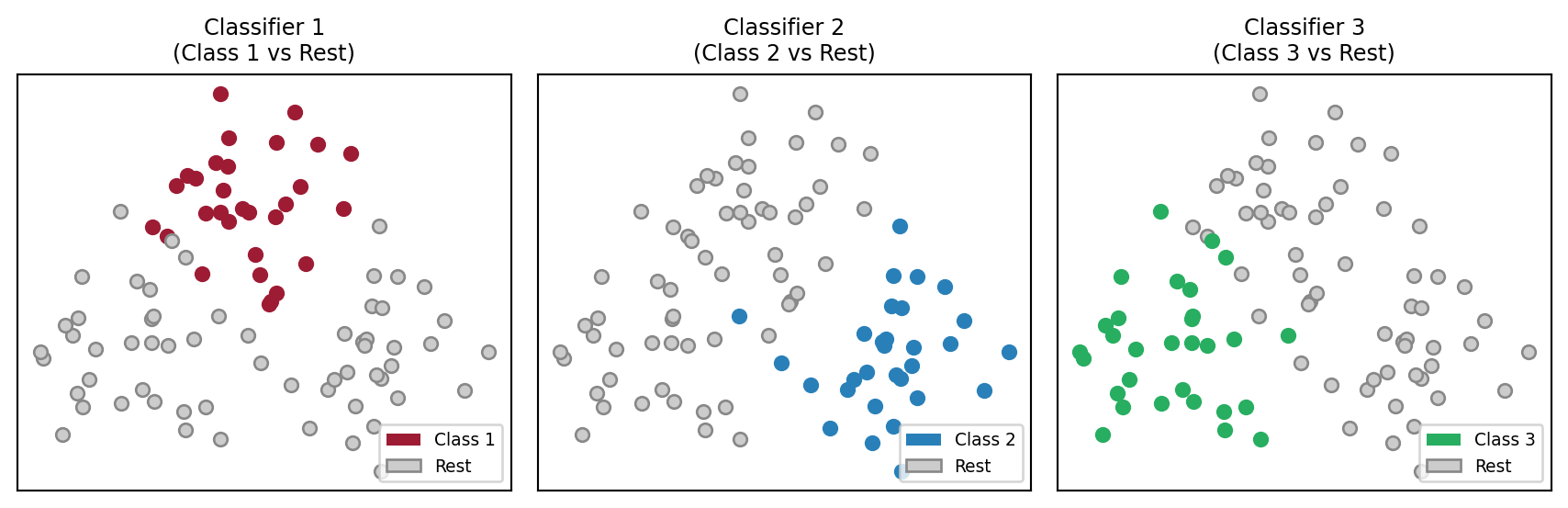
Each classifier learns to separate one class from the rest. Final answer: class with highest \(\hat{y}_k\).
Thank You!


